The goal of Reinforcement Learning (RL) is to learn a good strategy for the agent from experimental trials and relative simple feedback received. With the optimal strategy, the agent is capable to actively adapt to the environment to maximize future rewards.
This week, I will post some introduction paper in RL and some basic knowledge.
Introduction Books
- As introduced in syllabus, Reinforcement learning: An introduction by Richard Sutton and Andrew Barto is a good reference book for new comers in RL.
- Reinforcement Learning and Optimal Control by Dimitri Bertsekasis also a classic book. This book aims to introduce RL from dynamic programming angle.
- … will introduce more as we approach deeper
General Terminology of RL
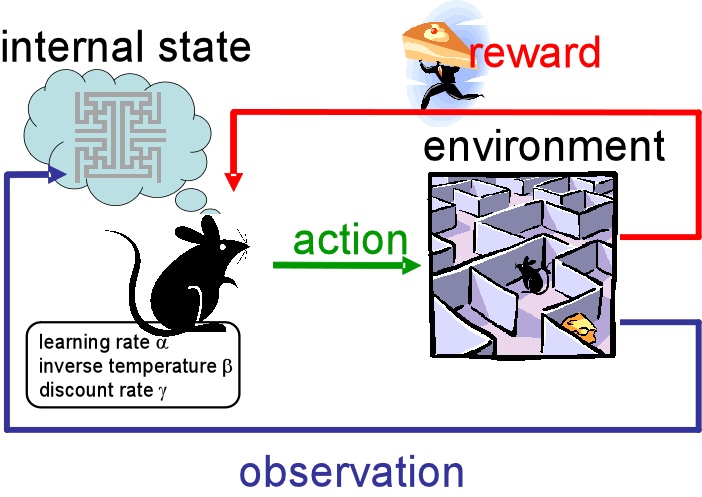
We may consider an agent in an environment with some specific goals. The agent is acting in an environment. How the environment reacts to certain actions is defined by a model which we may or may not know. The agent can stay in one of many states (s) of the environment, and choose to take one of many actions (a) to switch from one state to another. Which state the agent will arrive in is decided by transition probabilities between states (P). Once an action is taken, the environment delivers a reward (r) as feedback.
Methodologies of RL
Model-based RL vs. Model-free RL
The model defines the reward function and transition probabilities. We may or may not know how the model works and this differentiate two circumstances:
Know the model: planning with perfect information; do model-based RL. When we fully know the environment, we can find the optimal solution by Dynamic Programming (DP).
- Does not know the model: learning with incomplete information; do model-free RL or try to learn the model explicitly as part of the algorithm. Most of the following content serves the scenarios when the model is unknown. There are many general algorithms for model-free RL: Q learning, Sarsa, Policy Gradients.
Policy-based RL vs. Value-based RL
Policy-based RL is the most direct method of reinforcement learning. It can directly output the probability of various actions to be taken in the next step through the environment of sensory analysis, and then take action according to probability. Hence each action may be selected but the possibility is different. The value-based method output the value of all actions. We will choose the action according to the highest value. Compared with the policy-based method, the value-based decision is more determined and unrelenting. It will choose the highest value, while for policy-based method, even if the probability of an action is the highest, it is not necessarily selected.
For policy-based methods, we usually consider policy gradient while Q learning and sarsa are considered to be value-based methods. In addition, we have a method called Actor-Critic, which combines policy and value: actor will give action based on policy and critic will output values based on the action. It will accelerate the learning process based on policy gradient.
Monte-carlo update vs. temporal difference update
Reinforcement learning can also be categorized in another way, round updates and single-step updates. Imagine reinforcement learning is playing games, game rounds have start and end. Round update means that after the game starts, we have to wait for the game to end, and then summarize all the turning points in this round and update our code of conduct. The single step update is to update every step of the game, without waiting for the end of the game, so that we can learn while playing.
Now let’s talk about the method, Monte-carlo learning and the basic version of the policy gradients are all round-up updates, Q learning, sarsa, upgraded policy gradients, etc. are single-step update system. Because single-step updates are more efficient, so most of them are based on single-step updates.
On-policy vs. off-policy
The difference between on and off policy is whether to use updated observations as new data or not. The most typical on-policy method is Sarsa, and there is an algorithm that optimizes Sarsa, called Sarsa lambda. The most typical off-policy method is Q learning.